Vediamo un modo per eseguire degli script al boot di una macchina Linux. Il servizio che consente l’avvio e’ il systemctl
ad esempio creiamo uno script che all’avvio elimini tutte le regole di INPUT al firewall con il comando nano /root/regolafirewall.sh con il seguente contenuto :
#!/bin/bash
iptables -P INPUT DROP
ora con il comando chmod 777 /root/regolafirewall.sh concediamo i permessi di esecuzione allo script.
Ora creiamo il servizio che poi ci consentira’ di avviare all’avvio lo scritp portiamoci nella directory /etc/systemd/system e creiamo un file regolafirewall.service
all’interno di questo file scriviamo il seguente codice :
I vari parametri sono abbastanza chiari, i due ExecStart e ExecStop indicano i due script che devono essere richiamati al comando systemctl start <service> e systemctl stop <service>. Se lo script da lanciare e’ lo stesso, allora il parametro ExecStop non serve che sia specificato.
nella sezione Install il parametro WantedBy specifica che l’avvio del servizio vale per tutti gli utenti del sistema.
Ora per avviare il servizio/script possiamo lanciare il comando: systemctl start regolafirewall.service
Mentre per farlo partire al boot possiamo lanciare il comando: system enable regolafirewall.service
questo comando e’ permanente pertanto basta lanciarlo una volta e il servizio/script verrà eseguito ad ogni avvio .
Indirizzare l’output dei comandi shell in un file.
Cosa potrebbe serivre questa funzionalita’? Potrebbe essere necessario monitorare uno script controllandone l’esecuzione o gli errori, oppure potrebbe essere utile per indirizzare l’output del comando in un file su cui un’altro script recuperera’ le informazioni per eseguire altre funzioni.
Vediamo ora i diversi metodi per indirizzare l’output in un file
user@linux:$ comando > nomefile.txt
Questa modalita crea all’esecuzione di ‘comando’ un file di nome ‘nomefile.txt’ con all’interno tutto quello che sarebbe stato stampato a video nella shell di esecuzione, se il file non esiste lo crea, altrimenti se gia’ esistente lo sovrascrive. Dunque il simbolo ‘>’ sta a indicare la modalita di scrittura nel file. Vediamo quali sono le opsioni che possiamo usare :
simbolo
descrizione
>
Scrive in nuovo file, se esiste lo sovrascrive
>>
Scrive accodando alla fine del file se esiste, se non presente crea il file
2>
Scrive solo gli errori standard se file esiste lo sovrascrive. L’output del comando viene mandato a video
2>>
Come sopra ma accoda gli errori alla fine del file
&>
Scrive sia l’output che gli errori standard sul file e non visualizza nulla sul video
&>>
come sopra ma accoda alla fine del file
Un secondo metodo per reindirizzare e’ l’uso di tee. Se con il metodo precedente l’output del comando veniva reindirizzato sul file senza mostrare nulla a monitor, con tee e’ possibile indirizzare l’output nel file ed allo stesso tempo visualizzarlo sul monitor.
user@linux:$ comando | tee nomefile.txt
Nella tabella sotto sono riportati le varie versioni del comando e il loro risultato.
metodo
descrizione
| tee
manda a schermo il risultato del comando in piu scrive sul file, se il file esiste lo sovrascrive
| tee -a
manda a schermo il risultato del comando in piu scrive sul file, se il file esiste aggiunge il testo alla fine
|& tee
Manda a schermo sia l’output che gli errori standard in piu scrive tutto sul file , se esiste lo sovrascrive
|& tee -a
Manda a schermo sia l’output che gli errori standard in piu scrive tutto sul file se esiste aggiunge il testo alla fine
Tabella comandi shell di linux comparati per funzione
Con le nuove distribuzioni di linux alcuni comandi sono cambiati. Nella tabella successiva verdiamo i comandi piu’ utilizzati e i loro nuovi corrispondenti
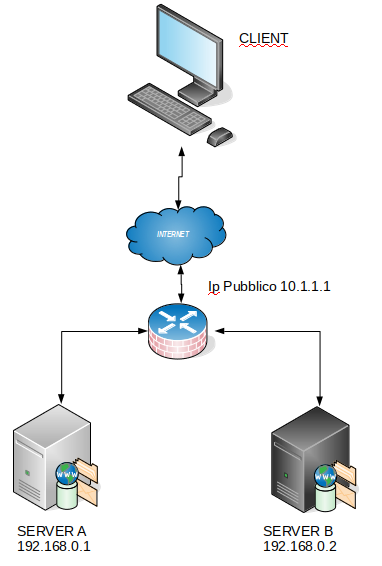
Analizziamo il caso in cui il client attraverso la rete internet, voglia accedere alla pagina web che risponde alla porta 8080 sul SERVER A con ip privato 192.168.0.1. Di questa pagina abbiamo una copia perfetta sul SERVER B con ip privato 192.168.0.2 che risponde sulla porta 80.
In condizioni normali, quindi, il client aprira’ il suo browser ed inserira’ nella barra degli indirizzi http://10.1.1.1:8080 corrispondente all’ip pubblico del router. La richiesta arriva al router che tramite le sue regole di nat indirizzera’ la richiesta al SERVER A il quale rispondera’ con la pagina web contenuta nel suo disco rigido.
Oggi pero’ abbiamo deciso di eseguire una manutenzione al WEB del SERVER A e chiaramente non possiamo permetterci che i CLIENT non abbia il servizio se richiesto. Non abbiamo accesso al firewall per modificare gli instradamenti e pertanto dobbiamo escogitare un trucco in modo che ad ogni richiesta della pagina WEB fatta al SERVER A sulla porta 8080, risponda il SERVER B sulla 80.
SOLUZIONE.
Sulle macchine linux ci viene in aiuto IPTABLES. IPTABLES e’ l’utility a riga di comando che ci permette di modificare le regole di firewall e di instadamento sui pacchetti che arrivano al o partono dal server.
Non faro’ qui un trattato su cosa sia un firewall e come lavori in quanto ci vorrebbero pagine e pagine di articoli ma mi limito brutalmente a dire che il firewall e’ quella parte di software che decide del destino dei pacchetti che nascono o che arrivano alla porta ethernet del server(detta veramente in modo brutale).
Vediamo ora cosa dobbiamo fare fisicamente sulla consolle della macchina SERVER A in modo che ad ogni richiesta che gli arriva sulla sua porta ethernet sulla porta 8080 giri la richiesta alla porta 80 del SERVER B.
Innanzi tutto per questo esempio ho usato due SERVER con installato DEBIAN 11, ma il concetto rimane valido per tutti i sistemi LINUX, prima operazione da fare e’ verificare che sia attiva la funzione FORWARDING del KERNEL mediante il seguente comando dal terminale.
root@SERVER_A:cat /proc/sys/net/ipv4/ip_forward
dovrebbe rispondere semplicemente con un 1. Nel caso la risposta sia 0 , sara’ necessario abilitare il forwarding e riavviare il servizio di rete con i seguenti comandi
root@SERVER_A: echo 1 > /proc/sys/net/ipv4/ip_forward
root@SERVER_A: systemctrl restart network
per le ultime verisioni di UBUNTU e DEBIAN
root@SERVER_A: systemctrl restart NetworkManager
Fatto questo dobbiamo inserire la regola nel firewall del SERVER_A tramite IPTABLES
Verifichiamo che la regola sia stata inserita con il seguente comando
root@SERVER_A: iptables -t nat -L --line-numbers
Rispondera con una serie di regole tra cui troverete le seguenti righe
Chain PREROUTING (policy ACCEPT)
num target prot opt source destination
1 DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80 to:192.168.0.2
A questo punto abbiamo finito, il client richiedera’ quindi la pagina web sempre all’indirizzo:porta pubblico http://10.1.1.1:8080 il router/firewall indirizzera’ la richesta sempre al SERVER A che ora pero’ invece di rispondere con il contenuto della pagina, rimandera’ la richiesta al SERVER B sulla porta 80 il quale mandera’ il contenuto della pagina WEB al client che l’ha richiesta.
Cosa dobbiamo fare invece se volessimo cancellare la regola e ripristinare la situazione iniziale? e sufficiente inserire il seguente comando
root@SERVER_A: iptables -t nat -D PREROUTING 1
dove 1 sta' per il numero di regola(num)
Ora il SERVER A riprendera’ a rispondere direttamente alle richieste sulla porta 8080.
Vediamo il comando per verificare se un processo e’ attivo. Questo e’ utile per verficare se un servizio e’ avviato oppure se e’ necessario farlo partire, oppure puo essere utile perchè magari il servizio e’ bloccato e voglio killarlo.
Per limitare l’uso della cpu ad un singolo processo in debian/ubuntu si puo utilizzare un programma scritto in C dal nome cputool.
Questo software non e’ installato di default ma si puo installare dai repository ufficiali con il comando:
$: sudo apt install cputool
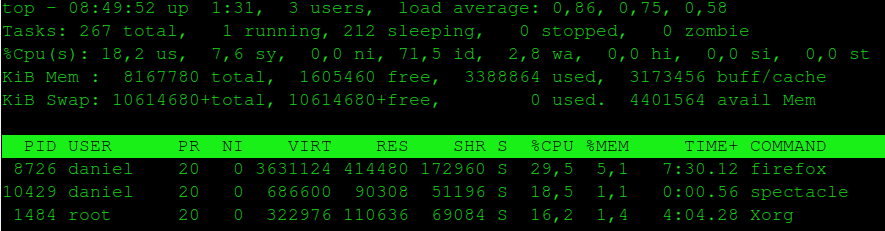
al termine dell installazione eseguire un top per identificare il pid del processo da limitare
$: top
se per esempio vogliamo limitare il processo firefox con id = 8726
scriviamo :
$: sudo cputool –cpu-limit 15 -p 8726
dove 15 sta ad indicare che il pid 8726 non potra’ utilizzare piu’ del 15% della cpu
chiaramente il prograsmma firefox risultera’ rallentato ma utilizzabile e non blocchera’ tutto il resto del sistema se dovesse superare la richiesta di CPU.
E’ possibile limitare non solo un pid ma anche un gruppo di pid